Skip to the content
Close
Acerca de
Contacto
Search For…
Search
Jacobo Nájera
Tecnólogo
Search
Menu
Search For…
Search
Close
Author
Jacobo Nájera
BPMgraph
Los cortes y bloqueos de Internet en América Latina en 2024
Una mirada sobre el ciclo de investigación en informática forense
Las tripulaciones marítimas que mantienen a África conectada a Internet
Instalación de Webtunnel
Gobierno de México recibe crítica por bloquear secciones enteras de la Internet segura
La historia detrás de un documental emblemático rescatado durante la dictadura de Chile
¿Por qué ocultamos la historia de la tecnología?
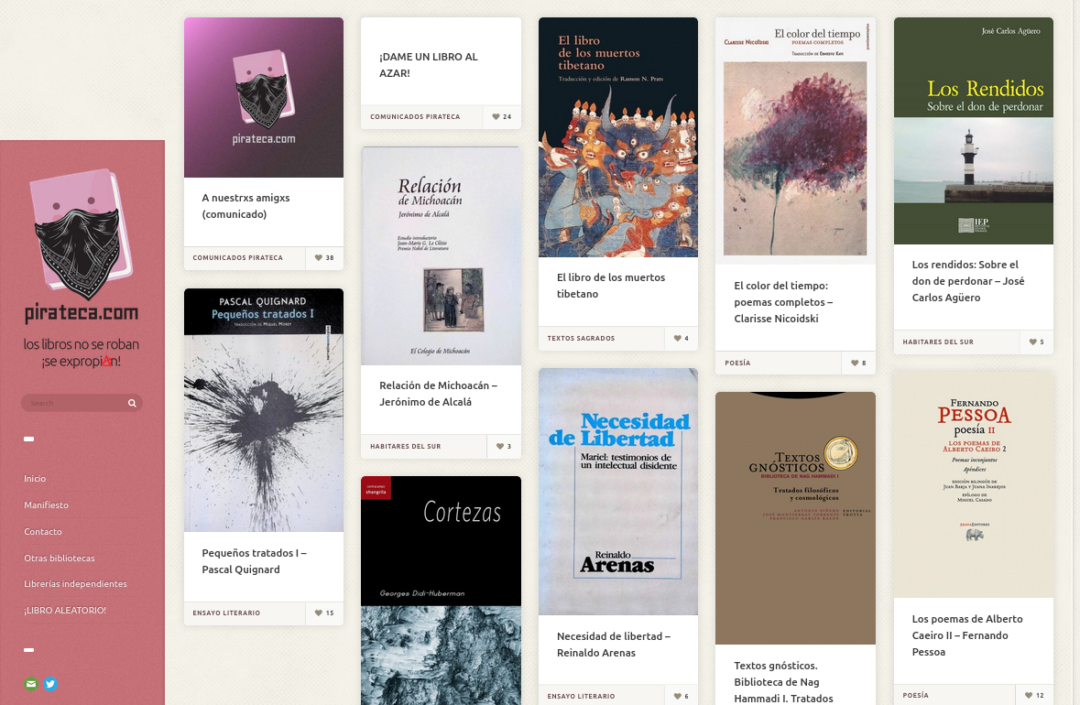
Una colectiva mexicana que piratea libros para compartir la cultura enfrenta bloqueos
Línea de vista o el lenguaje de las telecomunicaciones
Load More
Next Page